Con probabilidad casi uno, en un proyecto de ciencia de datos siempre se necesita un poco de código. Algunos científicos encuentran más conveniente trabajar directamente con un lenguaje de programación con librerías numéricas suplementarias mientras hay quienes prefieren pelearse con los datos con un lenguaje de programación y luego cargar el conjunto de datos en otra herramienta para su análisis exploratorio.
Las herramientas que existen para incorporarlas en el ciclo del trabajo de un científico de datos están las siguientes:
Excel – que para análisis simple de datos es una muy buena herramienta.
Tableau – que cuando funciona se obtienen gráficas muy bonitas.
Weka – es una herramienta para aplicar algoritmos de aprendizaje máquina prefabricados y trabaja con Java.
Estas herramientas trabajan con datos que están acomodados en tablas; sin embargo, la mayoría de las veces cada conjunto de datos necesita su propio tratamiento para obtener las características que se necesitan, en particular si los datos están en formas muy alejadas de una tabla. Es por esto que un científico de datos necesita dominar muy bien al menos un lenguaje de programación.
Inspección de los lenguajes de programación para un científico de datos (al menos los más populares).
Python. Es un lenguaje de programación de propósito general . Actualmente es el lenguaje preferido entre los científicos de datos porque tiene un balance entre flexibilidad de una escritura convencional con los músculos de buenos paquetes matemáticos. La primera versión de Python salió en 1991 y hay muchos paquetes que lo hacen muy poderoso.
R. Es un lenguaje de programación diseñado para estadísticos y con él es fácil hacer gráficas, está dotado de muchas funciones analíticas. Su desarrollo está basado en S que fue creado en los Laboratorios Bell en 1976.
Matlab® and Octave. Recientemente de manera general se está optando por software libre, es por eso que Matlab no es tan sonado como los dos lenguajes anteriores. Muchos científicos de datos que vienen de áreas como ingeniería o física suelen conocer bien Matlab. Un programa muy similar a él es Octave, con la facilidad de que se puede conseguir de manera libre.
SAS®. Es un programa muy bueno para hacer estadística aunque quizás no lo sea para ciencia de datos.
Scala®. Promete ser un buen lugar para científicos de datos aunque actualmente no tiene paquetes con los que se pueda hacer imágenes y análisis. Funciona muy bien para código de propósitos generales y para producción de software de gran escala.
Como conclusión es muy recomendable conocer Python, es un lenguaje famoso en el área en estos momentos, tiene muchos paquetes con herramientas para hacer buenos análisis y gráficas. Un buen libro para comenzar a enterarse de este lenguaje es Think Python de Allen B. Downey; otro libro enfocado a ciencia de datos es Python for Data Analysis por Wes Mackinney. Éstas son algunas opciones, pero hay gran cantidad de bibliografía que se puede consultar y de la que seguramente se puede aprender mucho.
En esta entrada y muchas otras subsecuentes que hablen de ciencia de datos, pondré información que me parece destacada del libro de Field Cady, The Data Science Handbook, con el fin de ir aclarando todo lo relacionado con este gran universo. Como lo introduce el autor:
Data Science o Ciencia de datos significa hacer análisis que por una razón u otra, requiere una cantidad sustancial de habilidades de ingeniería de software.
Por ejemplo:
Una base de datos puede ser tan grande que se requiera usar computación distribuida para hacer el análisis.
La base de datos puede ser tan enredada que sean necesarias varias líneas de código para desenredarla y poder analizarla.
Escribir grandes pedazos de software que implementen los análisis en tiempo real.
Un científico de datos necesita una buena dosis de los siguientes conocimientos: modelos estadísticos + software y programación + problemas de negocios, aparte de saber esto muy bien se debe relacionar de una manera que todo adquiera significado. Es un profesionista que pasa la mayor parte de su tiempo acomodando los datos de manera que se les puedan aplicar métodos estadísticos, para lo cual, necesita habilidades que un estadístico normal no tiene.
Las Etapas del trabajo de un Científico de Datos se muestran a continuación, cabe mencionar que para cada proyecto, estas etapas no se recorren una sola vez, ya que se obtiene en cada etapa información y perspectivas que pueden hacer que el problema necesite ser replanteado, o mover los parámetros con los que se hace el análisis.
Imagen del ibro The Data Science Handbook, de Field Cady, traducido.
1. Encuadrar el problema. Es necesario conocer el negocio y elaborar un problema bien definido para analizar; para lograr esto es importante hacer las preguntas adecuadas. Si el objetivo del análisis será informar a los interesados las conclusiones del análisis hay que conocer bien el problema, hacer preguntas sustanciosas que den un panorama amplio del negocio y de lo que hay que resolver.
Por otro lado, si el objetivo es entregar un software habrá que determinar varias cosas como qué lenguaje usar, cuál será el tiempo de ejecución, que tan precisas deben ser las predicciones.
En fin, se debe vislumbrar desde un principio qué sería una solución al problema. Acordar entre las partes involucradas cuándo se considerará al proyecto terminado y en qué casos será exitoso. Para ello es conveniente elaborar un documento que especifique claramente todas las cuestiones anteriores. Este documento se llama comúnmente “Statement of Work”.
2. Entender los datos. Involucrarse con ellos y con las cosas del mundo real que describen. Unas preguntas que para empezar estaría bien hacer son:
¿Qué tan grande es el conjunto de datos?
¿Es suficientemente representativo?
¿Contienen valores atípicos o ruido?
¿Puede tener datos artificiales?
A lo mejor, lo que más interesa saber a un científico de datos es si la base de datos contiene información que será útil para resolver el problema. En caso de que no, habrá que modificar los planes.
Luego viene pelearse con los datos, este proceso es uno donde los científicos de datos deben tener habilidades que los estadísticos no tienen. Se necesitan herramientas especiales para acceder a bases de datos para obtener los que se necesiten. Una vez que se tienen, hay que revisar que los datos estén completos; esto se puede hacer de muchas maneras dependiendo el formato del archivo obtenido, como abrirlo con lectores adecuados, hacer histogramas, gráficas de dispersión, hacer sumas sencillas que den luz sobre la precisión de los datos.
Finalmente, dentro del marco de entender los datos, hay que pasar un rato husmeando en ellos, creando visualizaciones de varias maneras, transformarlos para encontrar en ellos lo que hay que encontrar. Este momento es un buen lugar para dar rienda suelta a la curiosidad, se pueden calcular correlaciones. En particular, se puede desarrollar una intuición visual de los datos y hacer hipótesis concretas sobre lo que los datos pueden mostrar.
¡Los científicos de datos necesitan visualizaciones de los datos!
3. Extraer características que tengan sentido. En este paso hay que poner los datos en columnas y filas; cada fila corresponde a una entidad del mundo real y cada columna a un pedazo de información de esa entidad. Es decir, es conveniente tabular los datos.
Casi todas las técnicas de análisis operan sobre tablas, ¡Es muy importante tener una buena tabla!
Esta parte es la más creativa de la Ciencia de Datos y es un área donde se requiere un vínculo estrecho con los expertos en el campo para entender el significado del fenómeno e interpretar los números correctamente. A veces se trata de encontrar cómo medir lo que solicita con los datos que se tienen.
4. Poner estas características en un modelo y analizar. Un modelo que adivine si un cliente sigue siendo fiel, una regresión lineal que pronostique el precio del mercado para el día siguiente o un algoritmo que clasifique a los clientes en diferentes segmentos.
Es importante ajustar cuidadosamente los modelos y la ejecución, a veces se cambian los ajustes para la siguiente iteración si es que hay. Esta es la etapa donde se obtienen datos duros.
Si el cliente es humano se pueden presentar resultados de diferentes modelos, si es una máquina muchas veces se necesita sólo un algoritmo para ser usado en producción.
5. Presentar resultados y/o desarrollar código. En esta etapa es donde se necesitaran las habilidades de comunicar. Los resultados obtenidos se muestran en una presentación o en un reporte escrito. Se debe emplear un lenguaje apropiado para el público al que vaya dirigido y se logre la transmisión del mensaje.
Si el cliente es una máquina, tal vez a parte de lo anterior, se tendrá que hacer código que será ejecutado por otras personas. En este caso el resultado final consistirá de el código, la documentación de cómo correr el código y una muestra donde se ocupe el código recién creado que muestre su correcta ejecución.
6. Iterar el proceso. Una pregunta abierta al iniciar un proyecto en Ciencia de Datos es cuáles son las características que serán útiles y para qué modelo; en dado caso de ser necesario (que muchas veces lo es), tanto las características como el modelo se deben poder cambiar sin problemas.
El código debe ser flexible para poder hacer los cambios, debe ser lo suficientemente poderoso para que su desempeño sea eficiente y muy comprensible para editarlo rápidamente si los objetivos cambian. Por lo que los conocimientos de programación del científico de datos deben ser sólidos.
Todo lo anterior, se resume en una imagen, que hay que tener presente en el momento de una entrevista de trabajo.
Es un parque en el distrito Beşiktaş, Estambul, que primero fue un bosque, luego lo ocuparon como terrenos de caza, luego fue la arboleda del palacio de la costa, pero terminó siendo el parque que conecta el Palacio Çırağan con el Palacio Yıldız. Está rodeado por un alto muro que lo separa del barrio que lo alberga.
Durante el imperio otomano que duró más de seiscientos años (1299 – 1922), los sultanes no ocupaban una casa heredada por el sultán anterior, cada quien mandaba construir sus propios palacios. El terreno donde está el parque formó parte del imperio desde 1603, durante el reinado del sultán Ahmed I pero el Palacio Yıldız fue construido más de doscientos años después y fue usado por el sultán Abdul Hamid II en 1880.
El parque que parece más grande por dentro que por fuera; ciertamente es de los más grandes de Estambul. Está dividido en una parte abierta al público en donde están los pabellones Şale, Çadır y Malta que ahora son restaurantes y cafeterías, así como una fábrica de porcelana; y una parte privada que funciona como estancia para las visitas de estado.
Dentro del parque se pueden apreciar vistas muy bonitas de la ciudad. Se alcanza a ver, por ejemplo, la parte asiática, el Mar Mármara y a los barcos que esperan ahí su turno para atravesar el Bósforo y llegar a descargar mercancía en alguno de los países que tienen costa en el Mar Negro y en esa dirección otro emblema de la ciudad: Kız Kulesi, la torre de la doncella.
Hay muchos jardines donde las familias suelen hacer picnic y jugar toda la tarde; los niños se entretienen con las casitas que pueden subir y bajar. Hay dos lagos artificiales, un puente colgante sobre una cascada, un pedazo de pista con pendientes muy pronunciadas y caminos por donde los corredores más avezados entrenan. Se puede disfrutar también del canto de muchas aves que viven en los árboles. Es un lugar muy agradable para ir a leer.
Una teselación es una forma de descomponer el espacio en piezas más pequeñas de forma que se satisfagan las tres condiciones siguientes:
a) las piezas no deben dejar huecos
b) no se deben encimar
c) al rededor de cualquier punto del espacio hay una cantidad finita de piezas.
Las piezas más pequeñas se llaman mosaicos, ¿te suena esa palabra? ¿de dónde la conoces? Seguro de los pisos de algunas plazas, en las paredes de los baños, en los panales de abejas.
¿qué teselaciones tienes a tu alrededor?
Para hablar de teselaciones en el plano, diremos que hay dos tipos de polígonos: los regulares, que tienen todos sus lados de igual magnitud así como sus ángulos interiores; y los irregulares, donde no todos sus lados son iguales.
tipos de polígonos.
Las teselaciones regulares son formadas por un sólo tipo de polígono regular y sólo hay tres de éstas: una formada con triángulos equiláteros, otra con cuadrados y la tercera con hexágonos. También hay teselaciones semirregulares, son aquellas que están formadas por dos o más polígonos regulares. El teselado en la imagen del Kiosko Teselado del Palacio Topkapi es un ejemplo de teselación semirregular.
Kiosco Teselado en el Palacio Topkapı, Estambul.
También existen las teselaciones irregulares que son las formadas por polígonos no regulares, satisfaciendo las mismas tres condiciones mencionadas arriba. Estas teselaciones han permitido que artistas de diferentes épocas hayan creado mosaicos y dibujos impresionantes: como los mosaicos de los palacios de la Alhambra, los dibujos de Maurits Cornelis Escher.
Siguiendo con las teselaciones irregulares, a principios del siglo XX, el matemático ruso Gregory Voronoi encontró otra forma de dividir el plano en regiones que se definen a partir de un conjunto de puntos, al conjunto se le llama el conjunto de generadores.
La región asociada a cada punto consiste de todos los puntos cuya distancia a es menor que la distancia a con .
Cada celda se obtiene de la intersección de semi-planos, quedando regiones convexas.
En la siguiente imagen, los puntos azules son los con los que se generará la teselación; los polígonos irregulares que contienen a cada uno de esos puntos, son las regiones .
Diagrama de Voronoi, para un conjunto de puntos.
En la naturaleza aparecen diagramas de este estilo, por ejemplo en patrones de grietas en la arena debido a contracción por enfriamiento o sequía.
Las teselaciones de Voronoi, también llamadas partición o descomposición de Voronoi, ayudan a simular y estudiar muchos problemas en diversas áreas del conocimiento, como en astronomía, ayudan a identificar cúmulos de estrellas y de galaxias; en geografía se usan para analizar patrones de asentamientos urbanos; en ecología para modelar y analizar las competencias en las plantas y muchas más aplicaciones de las que te puedes enterar en este enlace.
Para terminar, un consejo: si un día te encuentras en Londres, puedes llevar este mapa contigo por si necesitas saber cual es la estación de metro más cercana a ti.
Metro de Londres. Imagen tomada de http://datagenetics.com/blog/may12017/index.html





 se le llama el conjunto de generadores.
se le llama el conjunto de generadores. asociada a cada punto
asociada a cada punto 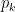 consiste de todos los puntos
consiste de todos los puntos  cuya distancia a
cuya distancia a  con
con  .
.
